Intro to Recommandation System
Problem formulation
可能会有99%的数据是不知道的(用问号表示)
因此可以去猜那些不知道的数据是多少
然后把得分最高的电影推荐给他就可以了
所以其实是一个矩阵补全系统
基本思想和方法
基于人口统计学的推荐系统
- 最简单的一种,只是根据系统用户的基本信息发现用户的相关程度,然后把相似用户喜爱的其他用品推荐给当前用户。
- 系统首先会根据用户的属性建模,比如用户的年龄,性别,兴趣等信息。根据这些特征计算用户间的相似度。比如系统通过计算发现用户A和C比较相似。就会把A喜欢的物品推荐给C。
- 优势
- 不需要历史数据,没有冷启动问题
- 不依赖于物品的属性,因此其他领域的问题都可无缝接入。
- 不足:
- 算法比较粗糙,效果很难令人满意,只适合简单的推荐
- 优势
content based recommender system(基于内容)
- 使用物品本身的相似度而不是用户的相似度。
- e.g 通过相似度计算,发现电影A和C相似度较高,因为他们都属于爱情类。系统还会发现用户A喜欢电影A,由此得出结论,用户A很可能对电影C也感兴趣。于是将电影C推荐给A。
- 假设有一些别的特征例如电影的浪漫成都或者动作成分含量(由专家弄出来的)
- 因此可以把原有的评分作为输入,把专家的预测作为y
- 做线性回归, 把每个用户的theta学出来
- 然后把theta和用户的评分做内积,得出那些问号的数据
协同过滤
- 基于物品的协同过滤
- 根本思想是
- 预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把和用户喜欢的物品相类似的物品推荐给用户。
- 假设a和c很相近,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A
- 根本思想是
如何计算相似度
- 基于余弦的相似度计算
- 通过计算两个向量之间的夹角的余弦值来计算物品之间的相似性
- 公式为
- 这个算法也有改进版(修正的余弦相似性)
- 由于余弦相似度度量方法中没有考虑到不同用户的评分尺寸问题,修正的余弦相似性度量方法通过减去用户对项目的平均评分来改善上述缺陷。
- 公式为
- 基于关联的相似度计算
- 计算两个向量之间的Pearson-r关联度
- 调整的余弦相似度计算
- 由于基于余弦的相似度计算没有考虑不同用户的打分情况,可能有的用户偏向于给低分,有的用户偏向于给高分,该方法通过减去用户的打分的平均值消除不同用户打分习惯的影响
- 基于余弦的相似度计算
预测值的计算
- 根据之前计算好的物品之间的相似度,接下来对用户未打分的物品进行预测,有两种预测方法。
- 1.加权求和
- 通过公式
- 通过公式
- 2.回归
- 1.加权求和
- 根据之前计算好的物品之间的相似度,接下来对用户未打分的物品进行预测,有两种预测方法。
推荐系统的其中一种实现
- 1.建立物品的同现矩阵
- 也就是按照用户分组,找出每两个物品再多少个用户中同时出现的次数
- 2.建立用户的评分矩阵
- 也就是每个用户对每个物品的评分
- 3.两个矩阵相乘,计算结果
- 1.建立物品的同现矩阵
- 基于物品的协同过滤
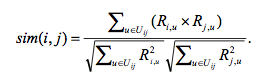
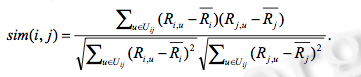
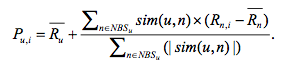
源码
- to be continued…
参考文献
- 《基于项目评分预测的协同过滤推荐算法》 邓爱林
- 相似度计算 http://blog.sina.com.cn/s/blog_7e11a6260101l9iq.html